|
|


Failure Statistics
APM calculates its failure statistics when a failure is resolved. When a failure’s dates are changed or it is canceled, APM can recalculate the statistics for all assets affected by the change. APM also provides templates for key performance indicators, which you can use to track failure statistics over time. This topic explains how APM calculates the failure statistics.Contents
Types of Statistics
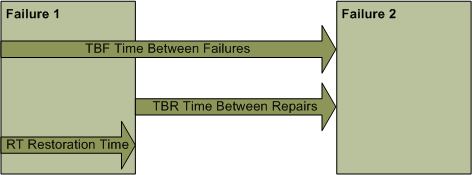
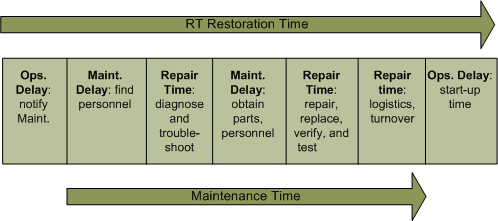
Failure Restoration Times
Delays
Key Performance Indicators
Calendar- and Indicator-Based Statistics
Determining the Previous Failure to Use in Calculations
You can view the chronology of assets and failures in the failure record’s Statistics view, Assets tab.Rolling Failure Statistics up the Asset Hierarchy
Recalculating Statistics for Modified Failure Records
When Occurred-On and Resolved-On Dates Change
When a Failure is Canceled